참고자료
-
원본 아티클 (Normalization vs Standardization — Quantitative analysis)
- Normalization vs Standardization
- Shay Geller is a full time AI and NLP researcher and Masters student of AI and Data Science at Ben Gurion University.
Intro
Stop using StandardScaler from Sklearn as a default feature scaling method can get you a boost of 7% in accuracy, even when you hyperparameters are tuned!
모든 ML 종사자는 Feature Scaling이 중요한 문제임을 알고 있습니다. (Read More Here.)
가장 많이 논의 된 두 가지 scaling 방법은 Normalization과 Standardization입니다. Normalization은 일반적으로 값을 [0,1]의 범위로 재조정하는 것을 의미합니다. Standardization는 일반적으로 데이터의 평균을 0으로하고 표준 편차를 1로 조정하는 것을 의미합니다.
이 블로그에서 나는 몇 가지 실험을 수행하고 당신이 다음과 같은 질문에 대답 할 수 있기를 바랍니다.
- 우리는 항상 우리의 features를 scale해야합니까?
- Single best scaling technique이 있습니까?
- 여러 scaling 기법들이 여러 분류 모델에 어떤 영향을 끼칩니까?
- 우리는 scaling 기법들을 hyperparameter 조정과 같이 중요하다고 생각해야 합니까?
여러 실험 환경에서 다른 scaling methods를 적용한 경험적 결과를 분석해 보겠습니다.
Table of Contents
- Why are we here?
- Out-of-the-box classifiers
- Classifier + Scaling
- Classifier + Scaling + PCA
- Classifier + Scaling + PCA + Hyperparameter Tuning
- All again on more datasets:
- Rain in Australia dataset
- Bank Marketing dataset
- Income classification dataset
- Income classification dataset - Conclusions
0. Why are we here?
첫째, 저는 Normalization와 Standardization의 차이점을 이해하려고했습니다. 그래서 저는 호기심을 만족시키는 수학적 배경을 제공하는 Sebastian Raschka의 훌륭한 블로그를 접하게되었습니다. Normalization 또는 Standardization 개념에 익숙하지 않은 경우, 5분정도를 들여 이 블로그를 읽기를 권합니다.
여기 Gradient descent method(신경 네트워크와 같은)를 사용하여 훈련 한 classifier를 처리 할 때 feature scaling의 필요성에 대한 Hinton의 훌륭한 설명이 있습니다.
Ok, we grabbed some math, that’s it? Not quite.
인기있는 ML 라이브러리 Sklearn을 확인했을 때, 나는 다양한 scaling 방법이 있다는 것을 알았습니다. 아웃 라이어가 있는 데이터에 다른 스케일러가 미치는 영향을 시각화한 훌륭한 자료가 있습니다. 그러나 그것들은 여러 classifier에 의한 분류 작업에 어떻게 영향을 미치는지 보여주지 못했습니다.
Feature scaling을 위해 StandardScaler(Z-score Standardization) 또는 MinMaxScaler(min-max Normalization)를 사용하는 많은 ML 파이프 라인 튜토리얼을 보았습니다.
왜 아무도 다른 scaling technique을 분류에 사용하지 않을까요?
StandardScaler 또는 MinMaxScaler가 항상 최상의 scaling 방법 일까요?
튜토리얼에서 왜, 언제 사용해야 하는지 설명이 없기 때문에 저는 몇 가지 실험을 통하여 이 기술들의 성능을 조사하기로 했습니다. This is what this notebook is all about.
Project details
많은 Data Science 프로젝트와 마찬가지로, 몇 가지 데이터를 읽고 몇 가지 기본 분류기를 사용하여 실험하겠습니다.
Dataset
Sonar Dataset. 여기에는 208개의 행과 60개의 feature가 있습니다. 금속 실린더에 반사된 초음파 신호와 원통형 모양인 암석에서 반사된 신호를 구별하는 분류 작업입니다.
 균형잡힌 데이터셋 입니다.
균형잡힌 데이터셋 입니다.
sonar[60].value_counts() # 60 is the label column name
M 111
R 97이 데이터 세트의 모든 feature는 0에서 1까지이지만, 각 feature 값이 1이 최대 값이거나 0이 최소값임을 보장하지 않습니다. 데이터 양이 작아 빨리 실험 할 수 있기 때문에 이 데이터 세트를 선택했습니다. 반면에, 분류하기 어렵고 어떤 분류 모델도 정확도 100%에 근접하지 않았기 때문에 의미있는 결과들을 비교할 수 있습니다.
우리는 마지막 섹션에서 더 많은 데이터 세트를 실험 할 것입니다.
Code
전처리 단계는 이미 완료했습니다. 따라서 결과 파일을 로드하고 작업만 하면 됩니다.
결과를 생성하는 코드는 제 GitHub에서 찾을 수 있습니다.
https://github.com/shaygeller/NormalizationvsStandardization.git
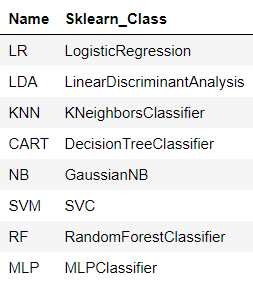
Sklearn에서 가장 인기있는 분류 모델 중 몇 개를 골랐습니다 :
사용한 scalers 입니다 :
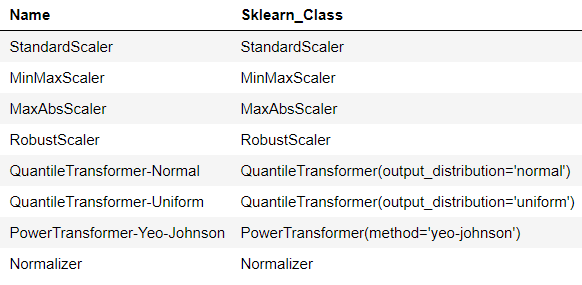
- 위 리스트의 마지막 스케일러 인 Normalizer와 이전에 논의한 Min-Max Normalization을 혼동하지 마십시오. Min-Max는 목록의 두 번째이며 MinMaxScaler로 명명됩니다. Sklearn의 Normalizer 클래스는 샘플을 단위 표준에 개별적으로 정규화합니다. 이는 컬럼 기반이 아니라 행 기반 정규화 기술입니다.
Experiment details:
- 재현성을 위해 필요한 경우 동일한 seed를 사용했습니다.
- 데이터는 무작위로 8:2 Train, Test set로 나누었습니다.
- 모든 결과는 train 세트의 10-fold 무작위 교차 검증에 대한 정확도 점수입니다.
- 여기서 test 세트에 대한 결과는 논의하지 않습니다. 일반적으로 테스트 세트는 숨겨져 있어야하며 분류기들의 결과는 오직 교차검증 점수로 정합니다.
- 중첩된 교차 검증을 수행했습니다. 매개변수 튜닝을 위한 5-fold 내부 교차 검증과 최상의 매개 변수를 사용하여 모델의 스코어를 얻기위한 10-fold 외부 교차검증을 시행했습니다. 또한 이 부분에서는 모든 데이터는 Train fold 세트에서만 가져옵니다.
- A picture is worth a thousand words :
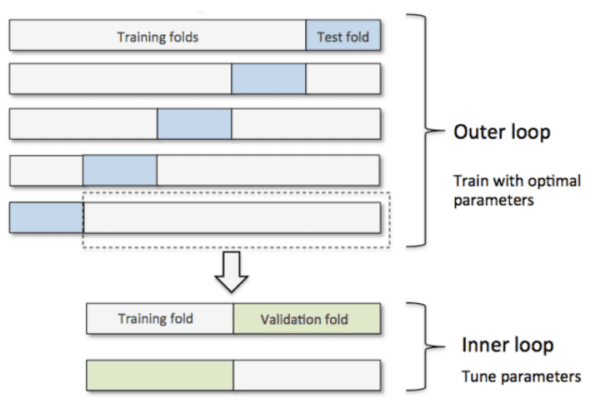
https://sebastianraschka.com/faq/docs/evaluate-a-model.html
Let’s read the results file
import os
import pandas as pd
results_file = "sonar_results.csv"
results_df = pd.read_csv(os.path.join("..","data","processed",results_file)).dropna().round(3)
results_df1. Out-of-the-box classifiers
import operator
results_df.loc[operator.and_(results_df["Classifier_Name"].str.startswith("_"), ~results_df["Classifier_Name"].str.endswith("PCA"))].dropna()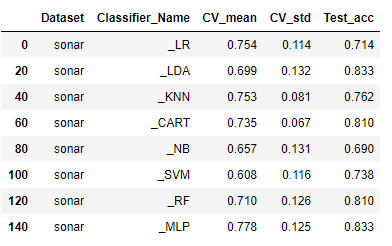
Nice Result! CV_mean 컬럼을 보면, 현재 MLP가 주도하고 있음을 알 수 있습니다. SVM은 최악의 성능을 보입니다.
표준 편차는 거의 동일하므로 평균 점수로 판단 할 수 있습니다. 아래의 모든 결과는 10-fold 교차 검증 랜덤 스플릿의 평균 점수가됩니다.
이제 각각의 scaling methods가 어떻게 분류기들의 점수를 변경하는지 살펴 보겠습니다.
2. Classifiers + Scaling
import operator
temp = results_df.loc[~results_df["Classifier_Name"].str.endswith("PCA")].dropna()
temp["model"] = results_df["Classifier_Name"].apply(lambda sen: sen.split("_")[1])
temp["scaler"] = results_df["Classifier_Name"].apply(lambda sen: sen.split("_")[0])
def df_style(val):
return 'font-weight: 800'
pivot_t = pd.pivot_table(temp, values='CV_mean', index=["scaler"], columns=['model'], aggfunc=np.sum)
pivot_t_bold = pivot_t.style.applymap(df_style,
subset=pd.IndexSlice[pivot_t["CART"].idxmax(),"CART"])
for col in list(pivot_t):
pivot_t_bold = pivot_t_bold.applymap(df_style,
subset=pd.IndexSlice[pivot_t[col].idxmax(),col])
pivot_t_bold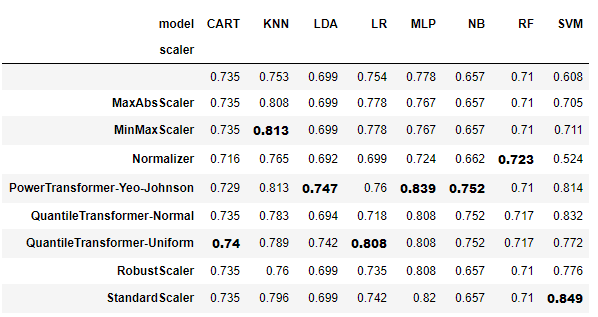
인덱스가 없는 첫 번째 행은 scaling method를 적용하지 않은 알고리즘입니다.
import operator
cols_max_vals = {}
cols_max_row_names = {}
for col in list(pivot_t):
row_name = pivot_t[col].idxmax()
cell_val = pivot_t[col].max()
cols_max_vals[col] = cell_val
cols_max_row_names[col] = row_name
sorted_cols_max_vals = sorted(cols_max_vals.items(), key=lambda kv: kv[1], reverse=True)
print("Best classifiers sorted:\n")
counter = 1
for model, score in sorted_cols_max_vals:
print(str(counter) + ". " + model + " + " +cols_max_row_names[model] + " : " +str(score))
counter +=1Best classifier from each model:
1.SVM + StandardScaler : 0.849
2.MLP + PowerTransformer-Yeo-Johnson : 0.839
3.KNN + MinMaxScaler : 0.813
4.LR + QuantileTransformer-Uniform : 0.808
5.NB + PowerTransformer-Yeo-Johnson : 0.752
6.LDA + PowerTransformer-Yeo-Johnson : 0.747
7.CART + QuantileTransformer-Uniform : 0.74
8.RF + Normalizer : 0.723
Let’s analyze the results
- 모두를 다룰 수 있는 단일 scaling 방법은 없습니다.
- Scaling으로 결과가 개선되었음을 알 수 있습니다. SVM, MLP, KNN 및 NB는 서로 다른 scaling 방법으로 크게 향상되었습니다.
- NB, RF, LDA, CART는 일부 scaling 방법의 영향을 받지 않습니다. 이것은 물론 각 분류기의 작동 방식과 관련이 있습니다. 분할 기준은 먼저 각 feature의 값을 정렬 한 다음 분할의 지니/엔트로피를 계산하기 때문에 Tree는 scaling의 영향을 받지 않습니다. 일부 scaling 방법은 이 순서를 유지하므로 정확도 점수는 변하지 않습니다. NB는 모델의 선수가 실제 값이 아닌 각 클래스의 개수로 결정되기 때문에 영향을 받지 않습니다. LDA는 클래스 간의 변동을 사용하여 상관 계수를 확인하므로 scaling하는 것이 중요하지 않습니다. (check this)
- QuantileTransformer-Uniform과 같은 일부 scaling 방법은 각 feature value의 정확한 순서를 유지하지 않으므로, 다른 scaling 방법에서 특정 분류기가 영향을 받지 않았던 것에 반해 위의 분류기에서도 점수가 변경됩니다.
3. Classifier + Scaling + PCA
우리는 PCA와 같은 잘 알려진 ML 방법이 scaling(blog)의 이점을 누릴 수 있음을 알고 있습니다. PCA (n_components = 4)를 파이프 라인에 추가하고 결과를 분석해 봅시다.
import operator
temp = results_df.copy()
temp["model"] = results_df["Classifier_Name"].apply(lambda sen: sen.split("_")[1])
temp["scaler"] = results_df["Classifier_Name"].apply(lambda sen: sen.split("_")[0])
def df_style(val):
return 'font-weight: 800'
pivot_t = pd.pivot_table(temp, values='CV_mean', index=["scaler"], columns=['model'], aggfunc=np.sum)
pivot_t_bold = pivot_t.style.applymap(df_style,
subset=pd.IndexSlice[pivot_t["CART"].idxmax(),"CART"])
for col in list(pivot_t):
pivot_t_bold = pivot_t_bold.applymap(df_style,
subset=pd.IndexSlice[pivot_t[col].idxmax(),col])
pivot_t_bold
Let’s analyze the results
- 대부분의 경우, scaling은 PCA를 사용하여 모델을 개선하지만 특정 scaling은 그렇지 않습니다. 대부분의 높은 점수를 가진 방법 인 “QuantileTransformer-Uniform”을 살펴 보겠습니다. LDA-PCA에서는 0.704에서 0.783으로 정확도가 8 % 향상되었지만 RF-PCA에서는 0.711에서 0.668로 정확도가 떨어졌습니다 (정확도는 4.35 % 하락했습니다).
- 반면 “QuantileTransformer-Normal”과 함께 RF-PCA를 사용하면 정확도가 0.766 (정확도가 5 % 향상되었습니다!)으로 향상되었습니다. PCA는 LR, LDA와 RF 만 개선하므로 PCA는 Magic 솔루션이 아닙니다.
- 우리는 n_components 매개 변수를 조정하지 않았습니다. 그렇더라도 PCA는 예측을 향상시킬 수 있다고 보장하지 않습니다. StandardScaler와 MinMaxScaler는 16 건 중 4 건에서만 최고 점수를 획득했습니다. 그래서 우리는 어떤 scaling 방법을 선택해야 할지 조심스럽게 생각해야합니다.
PCA가 scaling의 이점을 제공하는 알려진 Component 임에도 불구하고 단일 scaling 방법은 항상 결과를 향상시키지는 않으며 그 중 일부는 해를 끼칠 수 있다고 결론 지을 수 있습니다 (StandardScaler에서 RF-PCA).
데이터 집합도 여기에 큰 요소입니다. PCA에서 scaling 방법의 결과를 더 잘 이해하기 위해서는 보다 다양한 데이터 세트 (클래스 불균형, 다양한 기능 척도 및 수치 및 범주 형 기능이있는 데이터 세트)를 실험해야합니다. 저는 5 절에서이 분석을하고 있습니다.
4. Classifiers + Scaling + PCA + Hyperparameter Tuning
주어진 분류기에 대한 서로 다른 scaling 방법간에 정확도 점수에는 큰 차이가 있습니다. hyperparameters가 조정될 때 scaling methods 간의 차이는 작을 것으로 가정하고, 많은 분류 파이프 라인 자습서에서 사용되는 StandardScaler 또는 MinMaxScaler를 사용해 보겠습니다.
Let’s check that!

첫째, NB는 여기에 있지 않습니다. NB가 조정할 매개 변수가 없기 때문입니다.
거의 모든 알고리즘이 이전 단계의 결과와 비교하여 하이퍼 매개 변수 조정의 이점을 얻을 수 있음을 알 수 있습니다. 흥미로운 예외는 더 나쁜 결과를 얻은 MLP입니다. 신경망이 데이터에 쉽게 overfit될 수 있기 때문에 (특히 매개 변수의 수가 훈련 샘플의 수보다 훨씬 많은 경우), early stopping을 조심스럽게 수행하지 않았고, regularization을 적용하지 않았기 때문일 수 있습니다.
그러나 hyperparameters가 조정 된 경우에도 다양한 scaling 방법을 사용한 결과간에 큰 차이가 있습니다. 우리가 널리 사용하는 StandardScaler와 다른 scaling methods를 비교한다면, 다른 method 보다 정확도(KNN 컬럼)가 최대 7 % 향상 될 수 있습니다.
이 단계의 주된 결론은 parameters가 조정되었더라도 scaling 방법을 변경하면 결과에 큰 영향을 미칠 수 있다는 것입니다. 따라서 scaling 방법을 모델의 중요한 hyperparameter로 간주해야합니다.
섹션 5에서는 다양한 데이터 세트에 대한 심층 분석을 제공합니다. 이를 원하지 않으면 결론 섹션으로 자유롭게 뛰어 오십시오.
5. All again on more datasets
더 나은 이해와 더 일반적인 결론을 도출하려면 더 많은 데이터 세트를 실험해야합니다.
다양한 특성을 가진 여러 데이터 세트에 섹션 3과 같은 Classifier + Scaling + PCA를 적용하고 결과를 분석합니다. 모든 데이터 세트는 Kaggle에서 가져 왔습니다.
- 편의상 각 데이터 세트의 숫자 열만 선택했습니다. 다변수 데이터 세트 (숫자 및 범주 형 기능)에서 feature scaling하는 방법에 대한 지속적인 논의가 있습니다.
- 분류기의 hyperparameters는 default 입니다.
5.1 Rain in Australia dataset
Link
Classification task: Predict is it’s going to rain?
Metric: Accuracy
Dataset shape: (56420, 18)
Counts for each class:
No 43993
Yes 12427
5행의 샘플과 describe 입니다.


우리는 scaling이 features의 다른 scale로 인해 분류 결과를 향상시킬지 의문을 가질 것 입니다.
(위의 표에서 min max 값을 확인하십시오. 나머지 feature 중 일부는 더욱 악화됩니다).
Results

Results Analysis
- StandardScaler는 최고 점수를 얻지 못했고 MinMaxScaler도 없었습니다.
- StandardScaler와 다른 방법의 차이는 최대 20 %입니다. (CART-PCA 컬럼)
- scaling이 대개 결과를 향상시키는 것을 알 수 있습니다.
예를 들어 78 %에서 99 %로 뛰어 오른 SVM을 생각해보십시오.
5.2 Bank Marketing dataset
Link
Classification task: Predict has the client subscribed a term deposit?
Metric: AUC ( The data is imbalanced)
Dataset shape: (41188, 11)
Counts for each class:
no 36548
yes 4640
5행의 샘플과 describe 입니다.
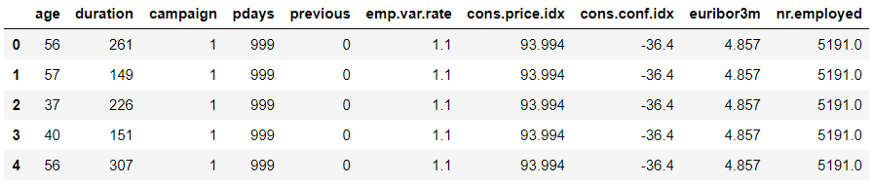
또 다시, feature들은 다른 scale 입니다.
Results

Results Analysis
- 이 데이터 세트에서 feautres의 scale이 다른 경우에도 PCA를 사용할 때 scale 조정한다고 해서 항상 결과가 향상되는 것은 아닙니다. 그러나 각 PCA 칼럼에서 2 번째로 좋은 점수는 가장 좋은 점수에 가깝습니다. 이것은 PCA의 components를 조정하고 scaling한다면 scaling하지 않는 것보다 결과를 개선할 수 있음을 나타냅니다.
- 다시 한번 강조할 것은 특출난 단일 scaling 방법이 없다는 것 입니다.
- 또 다른 흥미로운 결과는, 대부분의 모델에서 모든 scaling 방법이 그다지 영향을 미치지 않는다는 것입니다(일반적으로 1% ~ 3% 개선).
이것은 불균형한 데이터 세트이며, 매개 변수를 조정하지 않았음을 기억해야 합니다.
또 다른 이유는 AUC 점수가 이미 90 % 이상으로 높기 때문에 큰 개선을 보기가 더 어렵기 때문입니다.
5.3 Sloan Digital Sky Survey DR14 dataset
Link
Classification task: Predict if an object to be either a galaxy, star or quasar.
Metric: Accuracy (multiclass)
Dataset shape: (10000, 18)
Counts for each class:
GALAXY 4998
STAR 4152
QSO 850
5행의 샘플과 describe 입니다.


또 다시, feature들은 다른 scale 입니다.
Results

Results Analysis
-
scaling으로 결과가 크게 향상되었음을 알 수 있습니다. 다양한 feature scale 때문이라고 볼 수 있습니다.
-
우리는 PCA를 사용할 때 RobustScaler가 거의 항상 승리한다는 것을 알 수 있습니다.
이 데이터 세트에서 PCA 고유 벡터를 이동시키는 많은 이상값 때문일 수 있습니다. 반면에, 우리가 PCA를 사용하지 않을 때 그러한 이상치는 영향을 미치지 않습니다. 이를 확인하기 위해 데이터 탐색을 해야합니다. -
StandardScaler와 다른 scaling 방법을 비교하면 정확도가 최대 5% 차이가 납니다.
따라서 여러 가지 scaling 기법을 사용하여 실험해야 하는 또 다른 지표입니다. -
PCA는 거의 항상 scaling으로 이익을 얻습니다.
5.4 Income classification dataset
Link
Classification task: Predict if income is >50K, <=50K.
Metric*: AUC (imbalanced dataset)
**Dataset shape: (32561, 7)
Counts for each class:
<= 50K 24720
> 50K 7841
5행의 샘플과 describe 입니다.
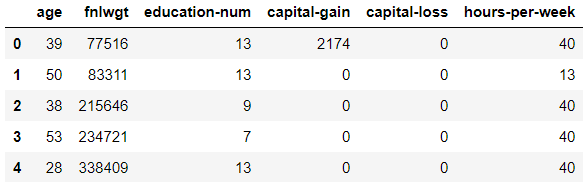
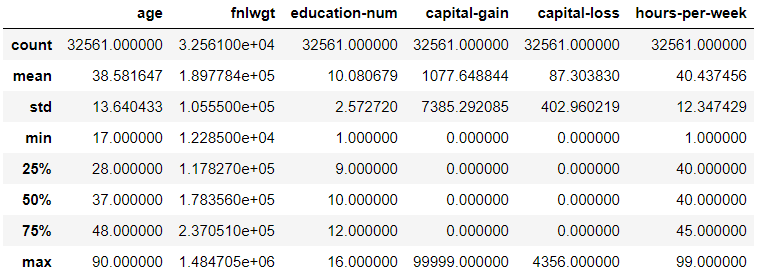
또 다시, feature들은 다른 scale 입니다.
Results

Results Analysis
- 여기서도 불균형 한 데이터 세트가 있지만 결과를 향상시키는 데 scaling이 효과적이라는 것을 알 수 있습니다 (최대 20%!).
이는 Bank Marketing 데이터 세트와 비교하여 AUC 점수가 (~ 80%) 낮기 때문에 큰 개선을 더 쉽게 볼 수 있기 때문입니다. - StandardScaler에 강조 표시되어 있지 않더라도 많은 열에서 최상의 결과와 동일한 결과를 얻을 수도 있지만 항상 그런 것은 아닙니다.
실행 시간 결과 (여기에 표시되지 않음)에서 StandatdScaler를 실행하는 것이 다른 여러 스케일러보다 훨씬 빠릅니다.
따라서 어떤 결과를 빠르게 얻기 위한 좋은 출발점이 될 수 있습니다. 그러나 모델에서 최대한 짜내려면 여러 scaling 방법을 사용해보십시오. - 다시 말하지만, 최고의 단일 scaling 방법은 없습니다.
- PCA는 거의 항상 scaling으로 이익을 얻습니다.
Conclusions
-
여러 가지 scaling 방법으로 실험하면 하이퍼 파라미터가 조정 된 경우에도 분류 작업에 대한 점수가 크게 높아집니다.
따라서 scaling 방법을 모델의 중요한 hyperparameter로 고려해야합니다. -
Scaling은 여러 분류기에 따라 다르게 적용됩니다. SVM, KNN 및 MLP (신경망)와 같은 거리 기반 분류기는 scaling에서 큰 이점을 얻습니다. 그러나 일부 scaling 방법에 대해 영향을 받지 않는 Tree(CART, RF)조차도 다른 scaling 방법으로 성능이 향상될 수 있습니다.
-
전처리 방법에 숨어있는 기본 수학을 아는 것이 결과를 이해하는 가장 좋은 방법입니다.(예를 들어, Tree가 작동하는 방식과 왜 scaling이 왜 영향을 미치지 않는지).
또한 모델이 Random Forest 일 때 StandardScaler가 적용되지 않는 것을 알면 많은 시간을 절약 할 수 있습니다. -
scaling의 이점이있는 것으로 알려진 PCA와 같은 전처리 방법은 scaling의 이점을 얻습니다. 그렇지 않은 경우 PCA의 components 수 설정이 잘못되었거나 데이터의 이상치 또는 scaling 방법의 잘못된 선택 때문일 수 있습니다.